


A/B-тесты – инструмент для того, чтобы зарабатывать. Это единственный инструмент, который помогает достоверно понять, хорошо мы сделали или плохо, самый прозрачный ответ на любой вопрос и возможность не прибегать к интуиции и не думать за пользователя.
Кроме того, А/В-тесты — это и хороший друг, на базе которого можно получать инсайты для имеющихся продуктов. А ещё, благодаря A/B-тесту улучшаются продуктовые метрики и NPS, поэтому тесты рекомендуется использовать всегда, если это недорого, и если мы ищем точки роста на существующих продуктах.
Когда в A/B-тестировании нет смысла?
Продукт на старте, и у него мало трафика
В такой ситуации вы рискуете не получить результаты в нужный срок. Когда, к примеру, тестируется посадочная страница с услугами стартапа или запускается новый продукт, еще нет большого трафика. Придется долго ждать, чтобы получить статистически значимый результат эксперимента. За это время тестируемая гипотеза может потерять актуальность.
Продукт для B2B, B2G или премиум-сегмента
У этих сфер высокая ценность каждого клиента. При A/B-тесте часть аудитории может увидеть «сырой» вариант решения и отказаться от сотрудничества. Такое может случится, если показать пользователям неудобный интерфейс или непонятные тарифы.
На рынке B2B и B2G-продуктов есть вероятность, что клиенты общаются между собой. Часть аудитории может узнать о том, что «избранным» предлагают особые условия, которые им недоступны.
Рассмотрим на примере. Сервис по размещению объявлений в сфере недвижимости тестирует новую модель оплаты. Корпоративные клиенты сервиса — застройщики и риелторские агентства, и часть из них увидели новые тарифы во время A/B-теста. Многие представители рынка общаются между собой. Вскоре недоумевающие пользователи звонят в отдел по работе с корпоративными клиентами, чтобы узнать о новых тарифах и почему они не видят их на сайте. Такая ситуация может снизить доверие клиентов к продукту, а еще исказить результаты самого теста.
Чем, в таком случае, можно заменить А/В-тестирование?
Иногда проверить гипотезу проще другими методами. Разберем, что это за методы и в каких ситуациях ими можно заменить A/B-тест.
Юзабилити-тестирование
Этим методом проверяют, насколько интерфейс удобен для пользователей.
Для исследования не нужно привлекать разработчиков, как в случае с A/B-тестом. Нужно создать новый интерфейс на уровне макетов, собрать интерактивный прототип и пронаблюдать, как пользователи с ним взаимодействуют. Потом выявить возможные проблемы и найти решение.
Fake door тест
Когда разработать фичу — сложно и долго, этим методом можно проверить, нужна ли она пользователям.
Для этого в интерфейс добавляется кнопка, за которой ничего нет, — fake door — и отслеживается, какой процент пользователей ее нажмет. За fake door обычно размещают сообщение о том, что раздел в разработке. Можно также добавить ссылку на опрос и таким образом собрать дополнительные данные для будущего продукта.
Релиз нового продукта на ограниченную аудиторию
Если есть достаточно времени, то вместо теста можно запустить продукт на один город, район или другую выделенную часть пользователей. Метод подходит, когда продукт локальный и требуется протестировать большие изменения бизнес-модели, или попробовать совершенно новый продукт. Например, беспилотное такси, которое тестирует Яндекс в одном из районов Москвы. Если результаты будут положительными, можно масштабировать продукт на всю остальную аудиторию.
Если всё же имеет смысл проводить A/B тест, пройдемся по проблемам и ошибкам, возникающим в ходе тестирований.
Какие основные фактические проблемы у тестов?
Из доклада Skyeng «Как заработать миллиард»:
- 90% тестов, как правило, проваливаются (не дают стат. значимого результата или идут в «-»). Можно зарабатывать на фичах, которые дают небольшой прирост (какие-то очевидные позитивные изменения)
- Если хотим достигать больших результатов – надо тестировать что-то большое, что-то значимое, что дает нам +10% к выручке всей компании своей продуктовой командой. И, конечно, такие гипотезы проваливаются достаточно легко и часто. Это риск, но это оправданный риск.
- Мало трафика (активного). Как следствие, длительность теста увеличивается. Это, в свою очередь, может давать простой в выкладке других фич в продукте.
- Долго и дорого потому что нужно:
- придумать гипотезу;
- описать задачу;
- нарисовать дизайн;
- спроектировать тест, все желаемые метрики;
- посчитать размеры выборок и тд;
- разработать, заверстать, протестировать, выпустить в продакшн;
- потратить время на набор группы;
- проанализировать результаты теста;
- написать отчет, сделать выводы.
Выходит, что практически любой тест становится долгим и дорогим. Значит, их не так много и мы не можем допустить 90% провалов при оценке. Поэтому, нужно:
- стараться не делать мелочи, а больше крупных изменений, чтобы не тратить всё время на получение совсем небольшого прироста в показателях;
- общаться со сконвертировавшимися/нет пользователями — возможно, узнаем что-то новое для корректировки гипотезы;
- при крупном изменении проводить UX-тестирование с прототипами на этапе MVP, и узнавать фидбек от клиентов до тех пор, пока не разработали полностью работающую дорогую версию;
- конвейерить тесты: на этапе проведения одного теста – готовить проведение следующего (один за другим).
Главные ошибки в тестированиях и к чему они могут приводить
Чаще всего ошибки происходят не из-за злого умысла, а из-за множества решений, которые аналитики должны принять на протяжении всего эксперимента: нужно ли собирать больше данных? Следует ли исключить некоторые наблюдения? Какие переменные следует учитывать при анализе результатов? Какие результаты отражать по итогу, а какие нет?
Все эти вопросы возникают в том числе у ведущих ученых, занимающихся анализом данных. Поэтому, чтобы избежать ошибок, важно делать предварительный дизайн эксперимента, описывать гипотезу и то, как будут анализироваться данные, предотвращая множество ошибок репликации, а также описывать абсолютно все результаты теста (как хорошие, так и плохие и нейтральные).
Теперь рассмотрим, какие ошибки могут быть.
«P-HACKING»
Может выражаться в:
- создании одинаковых тестов, до тех пор, пока не будет получен статистически значимый результат;
- чистке данных от «выбросов», которые таковыми не являются, чтобы снизить уровень p-value до границы и признать тест статистически значимым;
- накоплении данных, чтобы увеличить шансы статистически значимого результата (после прохождения заранее оговоренной точки принятия решения). Проблема не в том, что накапливать больше данных это плохо, а в том, что мы делаем это для тех гипотез, которые нам нравятся;
- остановке теста, как только значение p-value достигло границ стат. значимости (проблема подглядывания). Если вы начинаете проверять результаты с определенной частотой и готовы при наличии различий действовать, то вместо вопроса о том, является ли разница значимой в определенный заранее выбранный момент в будущем, вы спрашиваете, выходит ли разница за диапазон неразличимости хотя бы раз в процессе сбора данных. Это два совершенно разных вопроса. Даже если две группы идентичны, то разница конверсий может периодически выходить за границы зоны неразличимости по мере накопления наблюдений. Это совершенно нормально, так как границы сформированы так, чтобы при тестировании одинаковых версий лишь в 95% случаев разница оказывалась в их пределах. Поэтому, при регулярной проверке результатов в процессе проведения теста с готовностью принять решение при наличии значимой разницы вы начинаете кумулятивно накапливать возможные случайные моменты, когда разница выходит за пределы диапазона. Даже если тест достиг значимости, не прекращайте его. Ждите нужного объема выборки. Подробнее можно почитать в статье «Как не надо анализировать A/B-тесты. Проблема подглядывания».
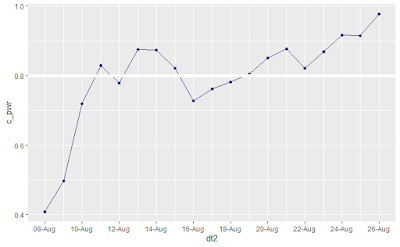
Что мы видим на графике: хотя под конец второго дня теста p-value < 0.05, power = 0.5 и решение принимать слишком рано.
Важно посмотреть хотя бы один бизнес-цикл (обычно — неделя) за динамикой p-value. Обычно в начале теста p-value очень волатилен, а потому смотреть за динамикой не только любопытно, но и важно. Например, мы могли бы увидеть, что на выходных различие между вариантами теста уменьшилось, а потому и мощность провалилась (< 0.8), т.к она зависит в т.ч от размера разницы между вариантами. Это полезный факт о том, как работает предложенное нами изменение с другой аудиторией (аудиторией выходного дня). Также существуют так называемые эффекты новизны, из-за которых мы можем попасть в ситуацию, когда вначале теста мы быстро достигаем сильную разницу между вариантами теста и, соответственно, высокую мощность теста, но, как только клиенты привыкают к «улучшению», эффект размывается. Поэтому, если ваше изменение высокорисковое и стоимость ошибки высокая, нужно понаблюдать за тестом дополнительные 2-3 бизнес-цикла, даже несмотря на достигнутую стат. значимость. В этом случае, при стабильном приросте между вариантами мы усилим мощность теста (>= 0.9) и, таким образом, уменьшим свои риски.
Проверяйте стабильность разницы показателей конверсии во времени. Пересекаются ли варианты? Линии плавные или с резкими перепадами?
«CHERRY-PICKING»
Когда из множества не значимых результатов вычленяют один значимый результат и не говорят о множестве остальных незначимых, либо декларируют только те результаты, которые лучше всего подтверждают исходную гипотезу.
«HARking» (Hypothesizing After Results Are Known)
Дословно – создание гипотезы после того, как известен результат теста. Игнорирование первоначальных гипотез и представление придуманных новых, как если бы они были придуманы до начала эксперимента. Такие гипотезы могут вводить в заблуждение как самих аналитиков, так и тех, кто принимает результаты эксперимента.
Значение p-value, равное 0,001, вероятность случайного появления результата всего 1 из 1000 раз, как правило, считается довольно значительной: очень маловероятно, что ассоциация возникла случайно, и, скорее всего, за этим стоит какой-то фактор. Это основано, конечно, на предположении, что вы не запускаете тысячи тестов, чтобы найти 1 случай из 1000 🙂 . Честная наука требует, чтобы ученые приступали к своим исследованиям с четкой, мотивированной гипотезой — например, что у нас есть основания полагать, что это конкретное химическое вещество вызывает этот тип рака, и мы хотим это проверить. По этой причине HARking считается крайне неэтичным.
Базовое предположение научного тестирования: ученый формирует априорную гипотезу на основе теории, которую затем подвергает проверке. Допустим, вы начали с вывода, к которому хотели прийти, и не особо интересовались научной этикой. В этом случае вы могли бы использовать статистическое тестирование для получения этого результата посредством выборочной отчетности.
В качестве примера предположим, что вы хотите установить связь между шоколадом и облысением. Вы собрали группу из 10 000 мужчин (довольно большой размер выборки), чтобы они сообщили о потреблении ими M&Ms, Twix и батончиков Mars за определенный период времени. Кроме того, вы регистрируете скорость облысения в группе с течением времени. Когда у вас есть данные о шоколаде и облысении, вы запускаете тесты на все, что только можете придумать. Мужчины, которые едят только M&M’s, лысеют в молодости? Молодые люди, которые едят и Mars, и M&Ms, но не Twix, чаще лысеют на макушке, чем спереди? Имеют ли пожилые неженатые мужчины, которые не занимаются спортом и ничего не едят, меньше случаев облысения? Запустите достаточное количество этих тестов, и в конечном итоге вы обязательно получите «статистически значимый» результат.
«Salami slicing»
Разделение данных на более мелкие фрагменты и описание результатов по этим «нарезанным» результатам. В таком случае, у нас применяются одни и те же гипотезы к «нарезанным» выборам, что может приводить к неверным выводам. Правило: одна выборка = 1 гипотеза.
Not publishing negative results
Отсутствие статистической значимости — это тоже результат, о котором нужно говорить. Как правило, во всех науках принято сообщать не все результаты, а только какие-то значительные и положительные, нежели что-то, что не сработало. Это означает, что мы перестаём знать о большом количестве гипотез и их результатах и то, что мы видим — слишком хорошо, чтобы быть правдой.
Более подробно со всеми ошибками можно познакомиться в статье «The 7 deadly sins of research».
Помимо этого, могут быть следующие проблемы, которые встречались в моей работе:
Нет мониторинга в первые часы работы теста
Некорректные тесты из-за возможных технических проблем, из-за чего весь тест будет невалиден и, скорее всего, запущен заново. А значит, часть выручки, которая ушла на ветку с вариантом B – потеряна.
Отсутствие качественной проверки всей системы и фронта и бэка
Несем потери в выручке, отправляя в вариант B трафик с некорректной работой бэка (к примеру, не такой же логикой как на A, что-то забыли перенести, например, скорость работы, определенную механику), т.к такой тест будет считаться некорректным и запущен, опять же заново, а потери в выручке уже были понесены.
Запуск нового дизайна/фичи во время теста
Влияет на изменчивость в поведении в обоих группах, что может ввести в заблуждение при оценке результатов.
Принятие решения по тесту в первые 2-3 дня после запуска
Весь тест «в топку», т.к при выкатке в продакшн через какое-то время можно будет увидеть неожиданное поведение в конверсиях и выручке.
«Чем больше тестов, тем лучше»
В какой-то мере это действительно так: чем больше тестов вы проводите, тем быстрее совершенствуетесь в этом и подтверждаете важность A/B-тестирования в целом.
- Если фанатично проверять каждый элемент страницы много раз, это не даст результатов для долгосрочного периода. Когда вы фокусируетесь на частоте и скорости, вы хуже структурируете эксперименты и упускаете ценные выводы.
- Уделите время подготовке. Убедитесь, что A/B тестирование соответствует гипотезе. Отслеживайте релевантные цели, чтобы генерировать максимум полезных идей, и ищите ответы на все вопросы.
- Не тестируйте много элементов сразу – это высокий риск ошибок при обосновании результатов. Например, резкий скачок конверсии одного из вариантов – не всегда признак того, что он лучший.
- Учитывайте опыт предыдущих экспериментов, когда создаете стратегию для следующих.
Дополнительные материалы:
7 грандиозных ошибок AB-тестирования: опыт экспертов
Если будет время – прочитайте довольно короткую и веселую статью, в которой 7 экспертов делятся своими грандиозными ошибками, с которыми сталкивались в своей карьере.
Про то, как доказать любую чушь статистически:
- Иллюстрация к пи-хаккингу — если много раз проводить один и тот же тест, можно получить нужные результаты: «Теорема о бесконечных обезьянах»;
- О том, какие найдены связи между казалось бы несовместимыми вещами: «Безумные корреляции».
Главные ошибки тестирования через призму науки
Вопросы, возникающие в ходе исследования могут приводить к разным ошибкам, вводящим в заблуждение всех, кто смотрит результаты теста. Это не проблемы новичков: в 2005 году эпидемиолог Стэнфордского университета Джон Ионнаидис сделал смелое заявление — большинство опубликованных результатов исследований ложны. Кто главные виновники? Систематические ошибки (смещения) между результатами теста и истиной, небольшие размеры выборок и p-hacking (про кризис репликации в науке можно почитать здесь: «P-Hacking, HARKing, and Science’s Replication Crisis — SimpliFaster»).